


In the previous blogs we introduced the RTP format and how these packets are sent across real-world networks. However, when they are received it is not as simple as just feeding them into an appropriate decoder. In this blog entry, we will examine some key ways in which transmission can disorder packets, and some preprocessing techniques to minimize the impact that this disordering has on media quality.
Handling Jitter
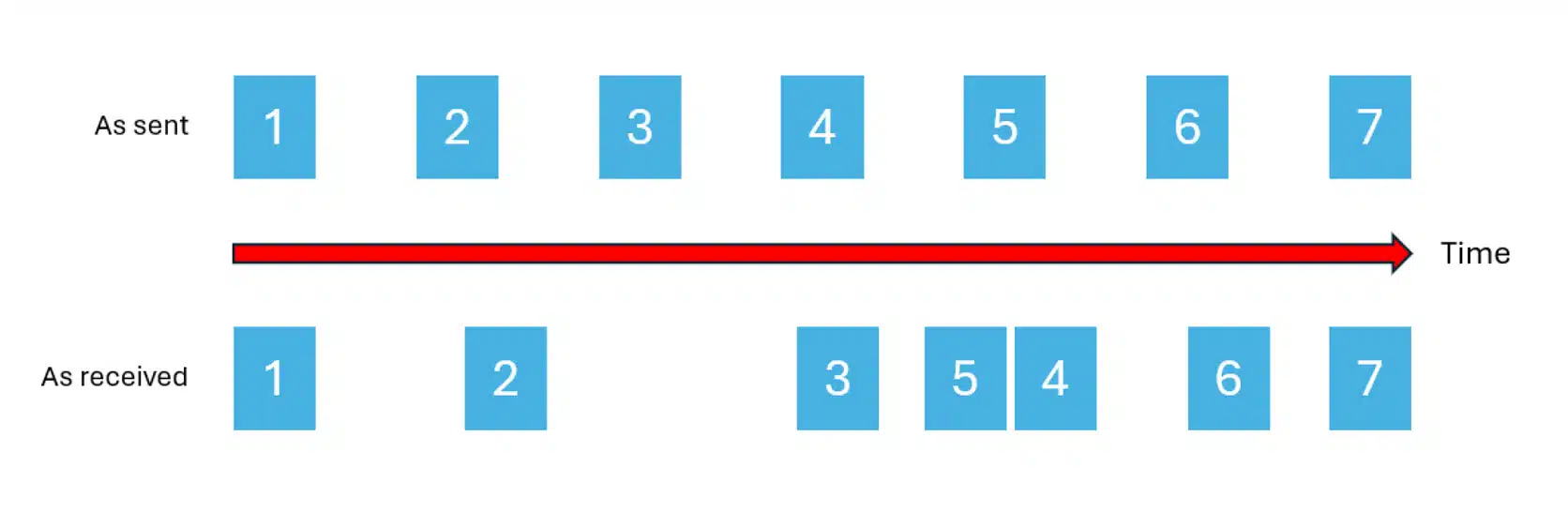
The key complication of receiving and processing UDP packets is that UDP is both lossy and the order of delivery is not guaranteed. As such, even if packets are sent by the far end at a perfectly monotonic rate, they may arrive in a ‘bursty’ fashion with varying gaps between them, some may be sufficiently delayed as to arrive out of order (i.e. after the packet sent subsequent to them), and some may never arrive at all. Coping with this is one of the key factors of delivering a good quality real-time media experience to users.
An illustration of packets being sent out in an orderly, paced fashion, but received with variable gaps between them with some packets out of order
Jitter is the term used to refer to the amount of variation within packet arrival intervals on a stream. Low jitter means that the packets are arriving at a relatively constant rate, while high jitter means burstiness and potentially re-ordering.
Simply feeding a stream, even with moderate levels of jitter, into a decoder can lead to a suboptimal experience – audio or video may be stretched out when packets are late to arrive and then accelerated when a burst of packets is received; audio may sound garbled while video may freeze or glitch. Any packets received out of order are effectively lost – once a decoder has processed packet 120 as best it can, there is no value in processing 119 anymore. As such, some form of mitigation is required, buffering being the most basic approach.
Buffering the input before feeding it into the decoder is a way for the receiver to mitigate the network-induced jitter. This approach enables packets to be re-paced to remedy their bursty arrival. As long as a reordered packet arrives before the preceding packet is decoded, the buffer can reorder it. These input buffers are referred to as jitter buffers.
The larger the buffer, the worse the level of jitter it can mitigate. However, it also directly impacts the latency of the media: a 100ms jitter buffer will add 100ms of latency to the media stream. As such the challenge with jitter buffers is to tune their size to mitigate as much impact from jitter as possible while keeping the latency acceptable.
The simplest form of jitter buffer is a static buffer – a buffer of fixed duration. This buffer duration might be hardcoded or be configurable by a user or admin. On a corporate WAN a relatively small static buffer (20-30ms) may be enough to handle the jitter introduced by the network while only introducing a minimal amount of latency. However, implementations that must perform well across a varied set of network conditions such as the public internet, mobile networks, and similar will likely discover any buffer size large enough to control some of the poorer-performing calls introduces a level of latency to the average call far too high to be acceptable.
A better system for these more diverse networks is one where the jitter buffer is small for well-behaved calls to minimise latency, but which automatically expands as jitter worsens, so that the larger buffer can better mitigate the effect of that higher level of jitter. These systems are called adaptive or dynamic jitter buffers. How they are implemented is beyond the scope of this blog, with scientific papers and patents covering various algorithms, but the general principles are that the buffer should begin small, be able to expand rapidly when jitter or loss increases (ideally quickly enough to avoid dropped packets due to bursts or reordering) and then return to smaller values more slowly as jitter improves while avoiding noticeably distorting the media due to the increased play-out speed. Beyond algorithms for when to grow and shrink, there are additional tricks, such as dropping buffered audio packets during periods of silence to opportunistically reduce the buffer size while avoiding sped-up audio.
Even when using an adaptive jitter buffer, it is recommended that there is some upper limit on its size, as beyond a certain point the latency cost begins to outweigh even noticeable media degradation. The simplest form of this is an upper bound beyond which the buffer will not grow, but can also include more complex implementations, such as making the buffer less and less willing to expand the larger it becomes.
Implementations may wish to have different thresholds for audio and video jitter buffer size, as higher amounts of latency may be acceptable for video compared to what is tolerable for audio. Note that, there can be considerable disagreement concerning the tradeoff between degradation and latency; some implementors consider 100ms of latency too high a price to improve quality, while others are willing to add a second or more of buffering to maintain audio quality.
Synchronisation
Jitter is not the only reason to potentially delay media streams on receipt; the other is synchronisation. This is the requirement to ensure that multiple media streams generated with a ‘common clock’ (e.g., as part of the same system) are synchronised so they line up. One example of this is lipsync – when participants’ speech from an audio stream matches their lip movements in the corresponding video stream.
However, there are a number of factors that can differentially delay one stream over the other. When this occurs, independently decoding them each one as packets become available will produce media that is visibly “out of sync”. In real-time media, audio frames are most commonly 20ms while most video runs at 30fps, meaning that the encoder takes ~33ms to encode each frame, resulting in video having a marginally higher latency than audio. Further, differential QoS markings that lead to audio being prioritised over video can mean that video packets suffer higher latency en route. Even if DSCP markings are the same or are not present, routers may route audio packets (which tend to be small) differently to video packets (which tend to approach the MTU limit). Finally, the streams may experience differential jitter leading to different size adaptive jitter buffers. All these factors ultimately lead to the packets being available for processing with a differential delay between them that require correction.
Synchronisation is technically possible between any number of media streams of any media types, though most implementations will limit themselves to syncing the main audio and video streams, if appropriate. Note that, implementations should not automatically assume that a main audio and main video stream from an endpoint can be synchronised – to be synchronisable they must share a synchronisation context. See CNAME in the SDES section of the coming RTCP blog series for more details.
Once an implementation has identified that two streams should be synchronised, it must convert from the arbitrary RTP timestamps with which frames are supplied to a common wallclock time (also called NTP time). This again relies on information provided in RTCP, in this case a pair of timestamps in the RTCP Sender Report – see that section of the coming RTCP series for specifics. This allows a receiving implementation to convert the timestamps in each stream to a timestamp common to all of them.
With common timestamps for each stream they can now be synchronised, if desired, by artificially delaying the decoding of some streams relative to the other. In the most common two-stream case, this means delaying the stream arriving first (usually audio) so that is synchronised with the stream arriving second (usually video). Note that, if implementation knows it takes longer to decode and render one media type than another, this should be considered when calculating which stream should be delayed and by how much, as well as taking the dejittering delay into account.
As with dejittering, implementations generally should have an upper limit on the latency they are willing to introduce to achieve lipsync; beyond a certain point, out-of-sync media is likely preferable to media that is synchronised but significantly delayed. This could be a threshold for the lipsync delay alone, or include any latency already introduced for dejittering. Additionally, as with dejittering, thresholds may be different for audio and video; the upper limit on audio delay might be just a few hundred milliseconds, while for video there might be no limit. Unlike dejittering, if the delay required to synchronise the streams exceeds the threshold, then it is recommended that the implementation applies no lipsync delay – if the streams are going to appear out-of-sync anyway, then it is best to minimise latency.
Source link



No Comment! Be the first one.