





Generative AI has redefined how we work, conduct business, and engage with the world. At Cisco, we have infused AI into the entire Webex ecosystem with one common AI Assistant that works in real time to power your workday. Today, it’s easier than ever to summon Cisco AI Assistant for Webex to transcribe and summarize your meetings, transform your writing style, help you brainstorm, and provide you with tailor-made answers to your questions.
Cisco recognizes the responsibility that comes with offering safe, high-quality technology that users can rely on. We have invested heavily in the evaluation of our generative AI powered technologies.
The Challenge of Evaluating LLMs
Evaluation is essential to developing machine learning products. Traditional metrics like F1 or word error rate, which work for tightly constrained tasks, fall short for generative AI models. These models perform open-ended tasks, presenting unique evaluation challenges:
- Subjectivity: LLMs generate responses that can be nuanced, context-dependent, and subjective. Different evaluators may perceive the same output as acceptable or unacceptable based on their individual preferences.
- Lack of Ground Truth: Many tasks allow for multiple valid answers, making it difficult to establish ground truth labels, which are required by most traditional metrics.
- Ineffective Metrics: Metrics like ROUGE or BERTScore, which are based on surface-level text similarity, often fail to capture more meaningful dimensions.
In the absence of reliable quantitative metrics, many teams leverage human judges to review the quality of LLM outputs. While it is the gold standard, human annotation is costly, slow, and difficult to scale—especially for lengthy inputs or frequent iterations.
Introducing the Auto Eval Platform
To address these challenges, we developed the Auto Eval platform for the teams within Cisco who would like to evaluate their generative AI systems. The goal of this platform is to take a data-and-metrics-driven approach to evaluation while minimizing the human effort involved and standardizing responsible AI development across Cisco’s products.
The platform’s custom-built metrics are designed to measure various aspects of system quality and have been thoroughly validated for accuracy. Additionally, most of the metrics are reference-free by design, meaning they do not need ground truth labels which are often unavailable or difficult to collect.
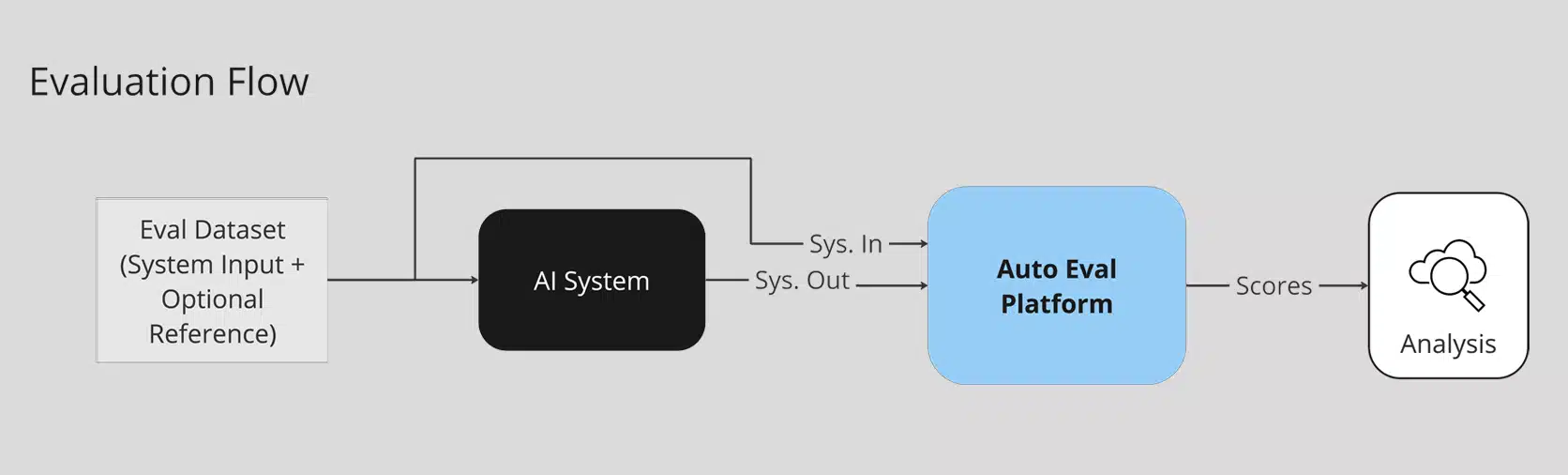
How It Works
- Curate Input Data: Collect inputs (e.g., meeting transcripts or questions) for evaluation. Labeled reference data are optional.
- Generate Outputs: Pass the inputs through the AI system under evaluation and save the outputs.
- Configure Metrics: Select and customize evaluation metrics based on the use case.
- Run Evaluations: Analyze system outputs against the selected metrics via the Auto Eval platform.
- Interpret Results: Use the platform’s built-in tools to visualize and interpret the scores.
Once a new AI system has been onboarded to this process, automatic evaluations can be run for a fraction of the time and cost of other methods. This scalable approach enables teams across the company to rapidly iterate, confidently deploy, and continuously monitor their AI solutions.
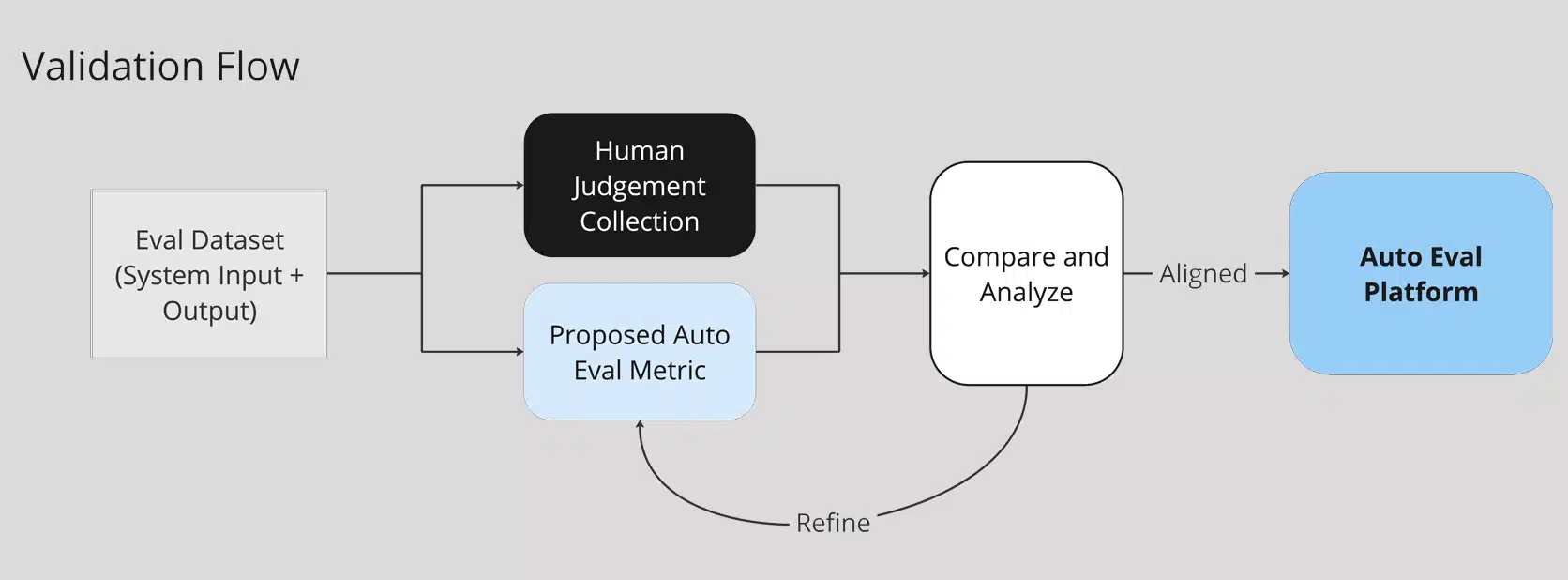
Validating Metrics
To ensure reliability, all metrics undergo a process of validation against human judgments. A small dataset of inputs and outputs is annotated, and rigorous statistical methods are used to confirm alignment between human and automated evaluations. To guarantee the effectiveness of our custom-built metrics, we universally set a high target (e.g., > 0.9 F1 score) as the quality bar of our metrics. Metrics that pass validation are added to the platform, minimizing human effort while maximizing reliability of the metrics.
Supported Use Cases and Metrics
The Auto Eval platform supports use cases such as summarization, retrieval-augmented generation (RAG), classification, and rewriting. To effectively evaluate these use cases, our team of scientists and engineers have implemented a suite of metrics grounded in research and best practices.
The metrics fall into three categories:
- LLM-Based: Metrics like fluency, faithfulness, and professionalism rely on LLMs as judges.
- Model-Based: Metrics such as toxicity, redundancy, and BERTScore leverage external models.
- Heuristic: Metrics like readability and n-gram duplication use deterministic algorithms.
The platform supports offline experimentation, continuous integration testing, and production monitoring, enabling teams to detect quality issues early and iterate quickly.
Metric Highlight: Professionalism
The Professionalism metric evaluates whether generated text meets enterprise communication standards. It flags:
- Evaluative language, which implies a judgement or assessment.
- Comparative language, which may suggest direct comparisons between companies, products, teams, or individuals.
- Subjective opinions, which express beliefs instead of facts.
- Language of conflict, which frame interactions as competitive or adversarial.
- Unprofessional language, which is too casual or not suitable for professional communication.
Developed specifically for the evaluation of Webex Meeting summaries, this binary classification metric was validated for alignment with a human-annotated dataset. The dataset comprised summaries generated from Webex’s own internal meetings (with attendees’ consent).
Limitations and Benefits
While scalable and cost-effective, automated metrics have limitations. LLM-based metrics are prone to biases like favoring longer responses or preferring model outputs over human ones. To mitigate these issues, the Auto Eval platform:
- Uses binary judgments instead of numeric ratings.
- Prompts LLMs for explanations to reduce errors and hallucinations.
- Samples multiple LLM responses for robustness.
- Combines results from different model providers to reduce bias.
- Validates all metrics against human judgments.
Despite the inherent limitations of automatic evaluation, this platform delivers enormous value to the teams within Cisco hoping to evaluate their AI systems.
Future Plans
In the coming year, we plan to onboard several new use cases, products, and corresponding metrics into the Auto Eval platform. Throughout this, we aim to ensure safe and high-quality language AI experiences for our customers, not just within Webex but across Cisco.
Stay tuned for Part 2 of this Evaluation Series!
Source link

No Comment! Be the first one.